
When Two Industries Converge: 3 new capabilities Boston Dynamics is integrating into robots with Generative AI

The structural reason AI agents dominate software but stall in engineering, manufacturing, and the physical world — and the framework for breaking through
By Vlad Larichev| Industrial AI Lead
Marc Andreessen’s 2011 thesis — software is eating the world — described a wave of digital diffusion. Software spread horizontally across every industry, replacing analog processes with digital ones. That thesis played out almost exactly as predicted. But it described breadth, not depth.
Today we’re watching something different unfold. AI agents are not spreading evenly across all software-touched domains. They’re concentrating — dramatically, disproportionately — in one specific area: software development itself. The tools that write, test, debug, and ship code are advancing at a pace that makes every other application of AI look tentative by comparison. Coding copilots have crossed from autocomplete to genuine agency. They propose architectures, implement them, run tests, interpret failures, and iterate — autonomously.
Meanwhile, in engineering, manufacturing, energy, construction, and pharmaceuticals — industries representing tens of trillions in global value — AI remains largely stuck in the role of a sophisticated retrieval engine. It summarizes documents. It generates text. It sometimes produces a CAD sketch or a process suggestion. But in every case, a human must manually verify whether the output is correct. The AI cannot close its own loop (more on this in our recent white paper with DFKI and Fraunhofer: Engineering AI)
This essay argues that this gap is not a matter of model capability, training data, or domain complexity. It is structural. It comes down to a single architectural property that software development possesses and most other domains do not: a compilation loop. And it argues that the defining challenge of the next decade is not building better AI models — it is making the physical world compilable.
Part I: The Compilation Gap

The Compilation Gap: Why AI Agents Dominate Software But Stall in Engineering Caption: Software development has a tight, fast, cheap feedback loop — compile, test, iterate in seconds. Engineering and manufacturing lack this loop, forcing humans into every validation step. This structural gap, not model capability, explains why agentic AI hasn’t crossed into physical-world domains.
Why LLMs Need Compilers
Large language models are, at their mathematical core, conditional probability estimators. They predict the next token in a sequence given all preceding tokens. This mechanism is extraordinarily powerful — powerful enough to generate fluent text, working code, plausible engineering specifications, and even novel chemical structures. But prediction and validation are fundamentally different operations.
An LLM generating a Python function can produce something that looks correct — syntactically clean, logically plausible, following the patterns it learned from millions of examples. Whether that function actually works — whether it handles edge cases, whether it terminates, whether it produces the right output for the right input — is a question the model cannot answer from its own parameters. It needs an external system to tell it.
In software development, that external system exists. The compiler catches syntax and type errors. The test suite catches logical errors. The runtime catches performance and integration errors. Each of these is a causal validation gate: a mechanism that evaluates the LLM’s output not against statistical likelihood but against formal correctness. The compiler doesn’t care what a typical Python function looks like. It cares whether this specific function conforms to the language specification.
This is the mechanism that turns a text predictor into an agent. The LLM generates, the compiler validates, the LLM reads the validation result and revises. Each cycle through this loop is an empirical test of the model’s output against reality — or at least against a formal proxy for reality. The loop is fast (milliseconds to seconds), cheap (fractions of a cent in compute), and produces a clear signal (pass, fail, or error with specifics).
Now consider what happens when an LLM tries to operate in a typical engineering domain. It generates a CAD geometry. Is the geometry manufacturable? There is no compile button. It proposes a set of simulation boundary conditions. Are they physically meaningful? No instant validation. It suggests a change to a manufacturing process plan. Will the revised plan meet cycle time and quality targets? Nobody knows until a human expert reviews it, and even then, the answer is often uncertain.
The model is the same. The capability is the same. What differs is the infrastructure around the model — the presence or absence of a compilation loop.
The Feedback Loop as the Unit of AI Agency
This insight has a precise implication: the unit of AI agency is not the model. It is the feedback loop.
A model without a feedback loop can only generate. A model with a feedback loop can iterate, and iteration is what turns generation into problem-solving. The tighter the loop — faster execution, cheaper computation, clearer signal — the more effectively the agent can navigate a solution space.
Software development has the tightest feedback loop of any cognitive domain in existence. That’s not an accident. It’s the result of seven decades of investment in compilers, interpreters, debuggers, test frameworks, type systems, linters, and CI/CD pipelines. The software industry built its own validation infrastructure, layer by layer, and AI agents are now reaping the accumulated benefit.
Other industries have validation infrastructure too — simulation tools, testing protocols, quality management systems. But this infrastructure wasn’t designed to be called by an AI agent. It was designed to be operated by a human. The interfaces are graphical, not programmatic. The setup requires expert judgment. The execution takes hours or days, not seconds. The results require interpretation.
The gap isn’t that other domains lack validation. It’s that their validation isn’t compilable — it isn’t fast, cheap, programmatic, and clear enough to serve as a feedback loop for an autonomous agent.
Part II: What Compilation Means Beyond Software
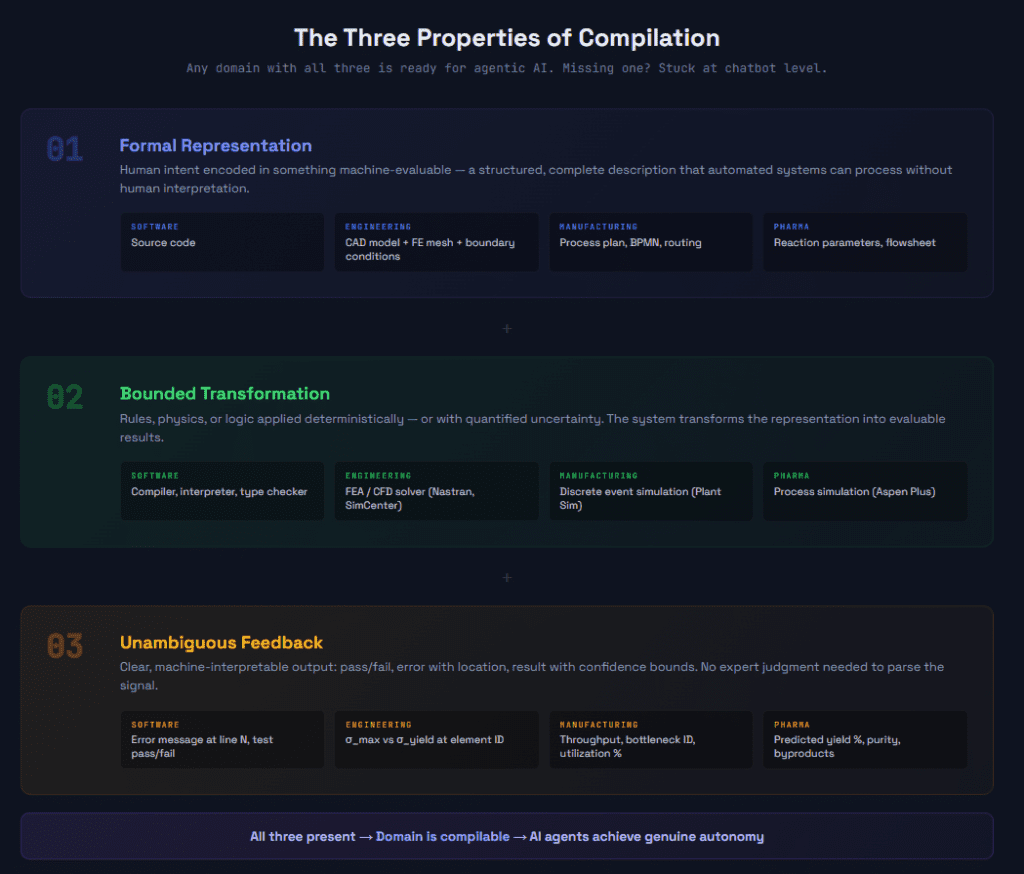
he Three Properties of Compilation: What Makes a Domain AI-Ready Caption: Compilation — whether in software or engineering — requires three things: formal representation, bounded transformation, and unambiguous feedback. Any domain with all three is ready for agentic AI. Any domain missing one stays at chatbot level.
The Abstract Compiler
Stripped to its essence, compilation is a three-part operation. Understanding these parts abstractly is what allows us to see where compilation can be constructed in domains that never had it.
Formal representation. The first requirement is that human intent must be encoded in a form that a machine can evaluate. In software, this is source code — a formal language with precise syntax and semantics. In structural engineering, it could be a finite element model: geometry, material properties, loads, and constraints, all represented in a format a solver can process. In manufacturing, it could be a process plan encoded in a format that a discrete event simulator can execute. The key property is that the representation must be complete enough for automated evaluation. A CAD model without material assignments and boundary conditions is like source code without a main function — it looks right, but you can’t compile it.
Bounded transformation. The second requirement is a system that can apply rules to the formal representation and produce a result. In software, the compiler applies language grammar and type rules; the runtime applies the program’s logic to inputs. In engineering, a finite element solver applies the equations of structural mechanics. In process engineering, a simulator applies thermodynamic models and mass/energy balances. The transformation doesn’t need to be deterministic in the mathematical sense — stochastic simulations are fine — but the uncertainty must be quantified. A simulation that says “stress is 245 MPa ± 12 MPa with 95% confidence” gives the agent something to reason about. A simulation that says “results may vary” does not.
Unambiguous feedback. The third requirement is that the output must be interpretable without expert judgment. A compiler error that says “type mismatch on line 47” is unambiguous. A structural simulation result that says “maximum von Mises stress exceeds yield strength at element 12,847” is unambiguous. An FEA run that produces a color plot requiring an experienced analyst to determine whether the result is meaningful — that’s ambiguous, and an AI agent can’t reliably use it as feedback.
The strategic takeaway: any domain where these three properties can be constructed is a domain that can be compiled — and therefore a domain where AI agents can achieve genuine autonomy.
Part III: The Compilation Readiness Ladder
This framework provides a diagnostic tool for evaluating where any given domain, industry, or specific workflow sits on the path to AI compilability. It also reveals where investment has the highest leverage.
Level 0 — Unformalized
At this level, domain knowledge exists primarily in the minds of experienced practitioners, in unstructured documents, and in organizational culture. There are no formal models that a machine could evaluate.
Think of how maintenance is handled in many industrial plants. Procedures are documented in PDF manuals. Troubleshooting relies on the experience of senior technicians who “know what that vibration pattern means.” When a new failure mode appears, resolution depends on someone having seen something similar before.
AI at Level 0 is limited to information retrieval and summarization. It can find relevant documents. It can extract and organize knowledge. But it cannot validate anything against ground truth, because ground truth isn’t formally represented.
Level 1 — Representable
At this level, the domain has formal, machine-readable models — but no automated way to evaluate them against physical or logical reality.
This is where most of engineering lives today. CAD models precisely define geometry. Requirements management systems like Polarion formally capture what a product must do. BPMN diagrams formally describe business processes. PLM systems track configurations and versions. The formal representations are rich and detailed.
But the connection between these representations and automated validation is manual. An engineer creates a CAD model and then separately, manually, sets up a simulation to evaluate it. A requirements engineer writes specifications and then, separately, a test engineer designs tests to verify them. The representations exist; the compilation loop does not.
AI at Level 1 can generate artifacts — draft a CAD model, write requirements, propose a process flow. But it has no way to evaluate whether what it generated is correct. It’s writing code with no compiler.
Level 2 — Simulatable (The Agentic Threshold)
This is the critical transition. At Level 2, formal models can be executed — submitted to a solver, simulator, or evaluator that returns quantitative results.
Finite element analysis validates structural integrity. Computational fluid dynamics validates aerodynamic performance. Discrete event simulation validates manufacturing throughput. Process simulation validates chemical reaction outcomes. Multibody dynamics validates mechanism behavior. Electromagnetic simulation validates antenna performance and signal integrity.
The tools exist. In many industries, they’ve existed for decades. But they were designed for human operators: graphical interfaces, manual setup, expert interpretation. What Level 2 requires for AI compilation is that these tools become programmatically accessible — callable via API or MCP, with parameterized setup, and machine-readable output.
When a simulation becomes callable as a function — when an AI agent can invoke it the way a coding agent invokes a compiler — the domain crosses the agentic threshold. The agent can now propose a hypothesis (a design, a process plan, a set of parameters) and test it. It gets quantitative feedback. It can iterate.
This is where AI tool use becomes AI compilation.
Level 3 — Continuously Compilable
At this level, the “compiler” isn’t a static model — it’s a living digital twin, continuously calibrated against real-world operational data.
A gas turbine digital twin doesn’t just simulate the physics of combustion and heat transfer. It incorporates sensor data from the actual running engine — temperature readings, vibration patterns, pressure measurements — and adjusts its model parameters to match observed behavior. A smart factory twin doesn’t just simulate the production line as designed. It reflects the actual state: machine availability, current work-in-progress, real cycle times.
At Level 3, the AI agent isn’t validating against a theoretical model of reality. It’s validating against reality itself, mediated through a twin that continuously narrows the gap between model and world.
This is the frontier. Very few domains are here today. But the trajectory is clear, and the organizations investing in Level 3 infrastructure are building the most powerful compilation loops possible — ones that get better over time as more operational data flows in.
Part IV: Compilation in Practice — Three Domain Analyses
The abstract framework is useful for strategic thinking. But compilation has to be built in specific domains, with specific tools and specific constraints. Let me walk through three domains in detail.
Structural Engineering: Simulation as Compiler
In a typical structural engineering workflow, the cycle looks roughly like this: a design engineer creates or modifies geometry in a CAD tool (NX, CATIA, SolidWorks). A simulation engineer imports that geometry into a pre-processing tool (Hypermesh, ANSA), builds a finite element mesh, applies boundary conditions and loads, and submits the model to a solver (Nastran, Abaqus, SimCenter). Results come back — stress fields, displacement fields, natural frequencies. The simulation engineer interprets these results and determines whether the design meets requirements. If not, the cycle repeats.
The total cycle time for one design-simulate-evaluate iteration is typically measured in hours to days. The human involvement at each stage is substantial: mesh quality judgment, load case selection, results interpretation.
Now consider what it takes to make this compilable. The geometry must be parameterized — defined not as a fixed shape but as a function of design variables that an agent can manipulate. The meshing must be automated — with quality metrics that serve as their own validation layer. The solver submission must be API-driven. And the results interpretation must be automated: extract the maximum stress, compare to the allowable, and return a clear pass/fail with specific information about where the design fails if it does.
Each of these steps is technically achievable with current tools. Parameterized CAD exists. Automated meshing with quality metrics exists. Solver APIs exist. Post-processing scripts exist. What’s missing is the integration — the stitching of these capabilities into a single, callable compilation function that an AI agent can invoke as easily as a coding agent invokes gcc.
Manufacturing: The Digital Factory as Compiler
Manufacturing process planning involves a different kind of compilation. The “source code” is a process plan: a sequence of operations, each with machine assignments, tooling selections, feeds and speeds, fixture requirements, and quality inspection points. The “compilation” question is: will this process plan actually produce the part to specification, on time, at acceptable cost?
Discrete event simulation (DES) tools like Plant Simulation or FlexSim can answer parts of this question. They model the factory as a network of resources, buffers, and routing rules, and simulate the flow of jobs through the system. The output includes throughput, resource utilization, work-in-progress levels, and bottleneck identification.
Making manufacturing compilable means connecting the AI agent’s process plan output to the DES tool’s input, running the simulation, and returning metrics the agent can act on. If the simulation shows a bottleneck at a specific work center, the agent can revise the routing. If throughput falls below target, the agent can adjust batch sizes or propose parallel operations.
The added complexity in manufacturing is that the “compiler” isn’t just logical — it’s also physical. A process plan that simulates well might still fail because of fixture interference, thermal distortion, or material variability. This is where Level 3 infrastructure — digital twins calibrated with real production data — becomes essential. The twin closes the gap between simulated performance and actual performance.
Pharmaceutical Process Development: Compiling Chemistry
Drug manufacturing involves process chemistry — defining the reaction conditions (temperature, pressure, catalyst, solvent, feed rates) that produce the active pharmaceutical ingredient at target yield and purity. Traditionally, this is experimental: chemists run reactions in the lab, measure outcomes, and iterate.
Process simulation tools (like Aspen Plus) can model reaction kinetics and separation processes. If the reaction kinetics are well-characterized, the simulator can predict yield, purity, and byproduct formation for a given set of conditions. This is the potential “compiler” for pharmaceutical process development.
The compilation loop would work like this: the AI agent proposes reaction conditions, the process simulator evaluates them, and the results (predicted yield, purity, energy consumption, waste generation) come back as quantifiable feedback. The agent revises and re-submits.
The particular challenge in pharma is model fidelity. Reaction kinetics are often poorly characterized for novel molecules, and the simulator’s predictions are only as good as the underlying kinetic model. This makes the “compilation” approximate — the confidence bounds on the feedback may be wide. But even approximate compilation is vastly more useful than no compilation. An agent that can narrow 10,000 possible reaction conditions down to 50 promising candidates through simulation — before any physical experiment — has compressed months of lab work into days of compute.
Part V: The Epistemological Shift
There is a deeper philosophical point embedded in the compilation argument that deserves explicit attention, because it affects how organizations should think about AI trustworthiness and governance.
LLMs, uncompiled, operate at the level of correlation. They produce outputs that are statistically consistent with correct outputs. This is useful — remarkably useful — but it provides no causal guarantee. An LLM can generate a structural analysis report that looks exactly like one written by an experienced engineer. But “looks like” and “is correct” are different claims, and the distance between them is where catastrophic failures live.
Compilation bridges this gap. When an LLM’s output passes through a physics solver, the result isn’t correlated with reality — it’s derived from a formal model of reality. When that formal model is further calibrated against measured data (Level 3), the derivation is anchored not just in theory but in observation.
This creates an epistemological stack:
Correlation (LLM alone) → Formal validation (LLM + simulation) → Empirical validation (LLM + calibrated twin) → Causal traceability (the full reasoning chain, captured and auditable).
Each layer provides stronger grounds for trust. And crucially, each layer makes the AI system auditable in a way that pure LLM output is not. You can inspect the simulation setup. You can examine the twin’s calibration data. You can trace the chain of decisions from initial hypothesis through each validation step to final conclusion.
This is the three-stage unlock that matters for both executives and regulators:
Compilable → Auditable → Optimizable.
Once a domain is compilable, it becomes auditable — because the compilation trace is a reasoning record. And once it’s auditable, it becomes systematically optimizable — because you can search the solution space with validated evaluation at each step.
In prior work, I’ve formalized this reasoning chain as the Digital Reasoning Thread (DRT) — a framework for capturing, connecting, and auditing AI reasoning as it flows across industrial tools and systems. Compilation is the foundational mechanism that makes DRT possible: you cannot trace reasoning that was never validated. The compilation loop produces the validated reasoning artifacts that DRT connects across disciplines and systems.
Part VI: The Historical Lens
The claim that “AI compiles the world” isn’t just a technology forecast. It’s a description of something that has been happening throughout the history of science — which AI is now positioned to accelerate dramatically.
Every major scientific advance has been, at root, the construction of a new compiler for a domain of reality.
Euclidean geometry compiled spatial relationships into axioms and proofs — enabling formal verification of spatial claims. Newtonian mechanics compiled motion into differential equations — enabling prediction and validation of physical trajectories. Thermodynamics compiled heat and energy into conservation laws — enabling calculation of engine efficiency before building the engine. Quantum mechanics compiled atomic behavior into wavefunctions — enabling prediction of chemical properties from first principles.
In each case, the pattern was the same: a domain of experience was encoded into a formal system that allowed hypotheses to be tested without running the full physical experiment. The formal system was the compiler. The experiment was the runtime.
What AI changes is who — or what — runs the iteration loop. The scientist used to be the one formulating hypotheses, setting up the formal evaluation, interpreting results, and revising. That loop — the scientific method, essentially — is what AI agents are now capable of executing autonomously.
But only if the “compiler” exists. Only if the formal system is accessible, callable, and returns machine-interpretable feedback.
This is why I describe the current moment as a transition from “software eating the world” to “AI compiling the world.” Software’s spread was about digitization — encoding the world in bits. AI’s deepening is about compilation — making those bits evaluable. The first wave asked: “Is your process digital?” The next wave asks: “Is your domain compilable?”
Part VII: Strategic Implications
For Technology Leaders
The implication is that the highest-leverage AI investment in most industrial organizations isn’t in the AI layer at all — it’s in the compilation infrastructure. Making simulations API-accessible. Making digital twin data queryable. Building automated post-processing that converts simulation output into machine-interpretable pass/fail signals. Creating parameterized design templates that an AI agent can manipulate.
None of this is glamorous work. But it’s the work that determines whether your AI investment yields autonomous agents or expensive chatbots.
For Engineering Organizations
The human role shifts. Engineers don’t disappear — they move from running the compilation loop to building and validating it. The structural engineer’s job isn’t to run FEA by hand. It’s to ensure the automated FEA pipeline is correctly set up: right mesh density, right element types, right boundary conditions, right convergence criteria. The engineer becomes the person who builds the compiler, not the one who pushes code through it.
This is a fundamental change in the nature of engineering expertise. Knowing how to do a task is no longer sufficient. You need to know how to formalize the task well enough that an agent can do it — and, critically, how to verify that the agent’s compilation pipeline produces trustworthy results.
For Regulators and Standards Bodies
Compilable AI is auditable AI. The compilation trace — the sequence of inputs, transformations, and validated outputs — provides exactly the kind of reasoning record that regulators need. It is far more trustworthy than asking an LLM to “explain its reasoning,” because the explanation is grounded in formal validation rather than post-hoc rationalization.
Standards bodies should consider defining what “compilable AI” means in their specific domains: what validation infrastructure must be in place, what confidence bounds must be achieved, what traceability must be maintained. This is a concrete, actionable path toward AI governance in safety-critical industries.
Conclusion: The Race to Compilability
Software development is a $600 billion market. AI agents are transforming it because it was already compilable. Manufacturing, energy, construction, pharmaceuticals, and infrastructure are collectively worth tens of trillions. They remain largely uncompiled.
The compilation gap is the barrier between AI’s current economic impact and its full potential. Every simulation made API-accessible, every digital twin made queryable, every validation loop made tight and fast — each is an expansion of the territory that AI can reason about with genuine autonomy.
“Compilable” is the new “digital.” The question that defined the last two decades — has your business digitized? — is giving way to the question that will define the next two: is your domain compilable by AI?
The organizations that answer yes first will see the same magnitude of productivity transformation that AI agents brought to software development — but applied to physical products, processes, and systems whose value dwarfs the software industry. Those that answer no will find their AI investments plateauing at chatbot-level impact. Helpful. But fundamentally bounded by the absence of a causal feedback loop.
The race isn’t to adopt AI. It’s to make your world compilable.
Vlad Larichev is Industrial AI Lead at Accenture Industry X, where he works at the intersection of AI, simulation, and industrial engineering. He is the creator of the Digital Reasoning Thread (DRT) framework for traceable AI reasoning across industrial systems. His work focuses on the structural challenges of deploying autonomous AI agents in physical-world domains.
Connect: [LinkedIn] | [GitHub — Digital Reasoning Thread] | [Related: The Digital Reasoning Thread — A Unified Reasoning Layer for Industrial AI]